5x Faster than Rust Standard Channel: Optimizing Burn Communication Layer

Disclaimer
The techniques used to achieve this speedup involve specialized, unsafe implementations and memory arena strategies tailored specifically for high-performance asynchronous task execution. While these might not be the idiomatic way to write every Rust application, they are ideal for projects like Burn where every microsecond of CPU latency matters.
Motivation
In recent iterations of Burn, we faced a dilemma. To support complex, recursive states
like our autodiff graph, fusion tensor compiler, and the CubeCL server, we relied on
reentrant mutexes. They allowed for recursive calls, necessary for profiling and
autotuning, but the locking overhead was problematic, especially when multiple GPUs and
threads were involved. In a well-designed asynchronous system, fire-and-forget is the
go-to choice, where tasks are enqueued onto a dedicated runner thread without waiting for
completion. However, when we swapped the mutex for a standard std::sync::mpsc[1] channel, the system actually got slower.
Results
Our initial attempt at reimplementing the communication layer using standard channels introduced a major performance regression. By moving to a custom, zero-allocation task enqueuing system, we resolved the performance issues of the new communication layer and actually improved framework overhead when multiple threads are involved, which was our primary goal from the start.
Benchmarks
We performed several benchmarks to measure the performance differences of our new communication layer. First, we isolated the channel implementation using random tasks that do not involve the GPU. Then, we conducted benchmarks directly within Burn, measuring framework overhead by launching small tasks.
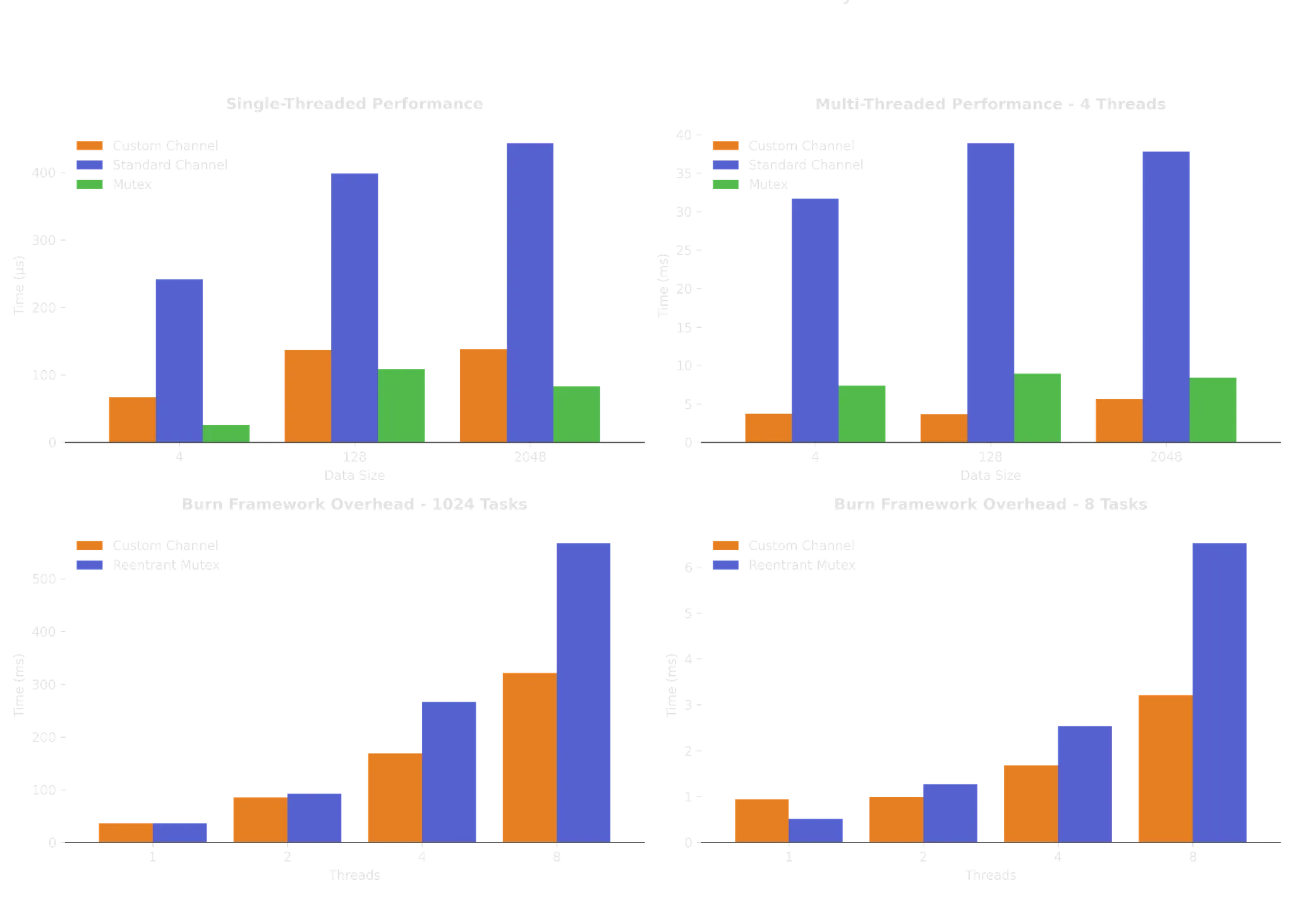
The benchmarks reveal that a mutex remains the fastest way to perform computations with a single thread. This is expected, as it avoids data copying entirely and lacks contention when only one thread is active. When multiple threads are involved, however, it is a different story: the custom channel can be up to 10 times faster than the standard channel and roughly 2 times faster than the mutex. When measuring framework overhead with 8 threads, we can execute nearly twice as many tasks compared to using a reentrant mutex as the communication layer.
Implementation Details
Why was a dedicated channel slower than a lock? The answer was memory allocation. Our API
relies on sending closures over a channel. In standard Rust, this usually looks like Box<dyn FnOnce()>. Because these closures often exceeded 1000 bytes, we were placing massive pressure on
the allocator. With multiple threads attempting to allocate and deallocate these boxes
simultaneously, the contention was worse than the original mutex lock. To solve this, we
moved away from the safety of standard trait objects and embraced pointer manipulation and
pre-allocated memory.
First, we addressed zero-allocation task enqueuing by replacing standard boxing with a tiered Double-Buffer Arena. Small closures (≤ 48 bytes) are now inlined directly into a 64-byte Task struct, aligned to CPU cache lines to prevent false sharing, while larger closures (up to 4KB) use a pre-allocated memory arena to bypass the global allocator entirely. We only fallback to a standard Box for closures larger than 4KB, which represent a negligible fraction of our workloads.
Second, we implemented lock-free double buffering to eliminate the contention typical of standard ring buffers. Using a Double-Buffering Swap strategy, producers write to a client buffer using atomic Acquire/Release semantics. When the runner thread is ready, it performs a single atomic swap to move the entire batch of tasks into a private server buffer, allowing the runner to execute tasks sequentially with zero interference from producers.
Finally, we ensured recursive safety via Thread Local Storage (TLS)[2]. To handle the recursion that originally necessitated reentrant mutexes, the runner thread now uses TLS to detect if it is attempting to submit a task to itself. If it is, the task is executed immediately and eagerly rather than being enqueued, preventing deadlocks without the heavy overhead of reentrant locking.
Conclusion
Should you implement a custom channel instead of relying on the standard library? Probably not. But can you significantly outperform general implementations when you have deep knowledge of the objects being transferred? Absolutely.
Our new device handle is a testament to that. It provides an elegant way for independent device services to share a communication channel with minimal overhead, moving away from global static mutexes toward a highly optimized, specialized API. Because the implementation remains centered around FnOnce, it stays flexible and intuitive to use. If you are looking for inspiration on squeezing every drop of performance out of your task execution, we encourage you to dive into the source code[3].